MotionLLM: Multimodal Motion-Language Learning
with Large Language Models
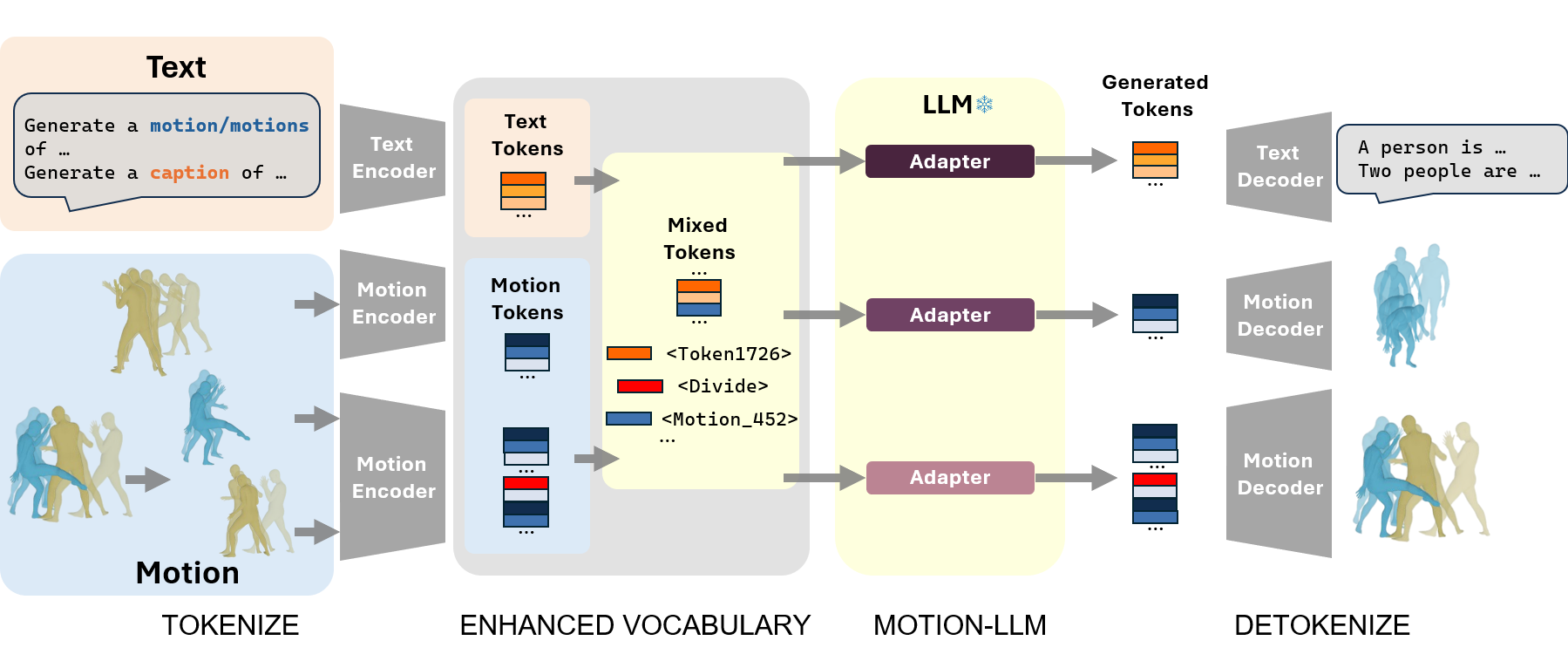
Recent advancements in Multimodal Large Language Models (MM-LLMs) have demonstrated promising potential in terms of generalization and robustness when applied to different modalities. While previous works have already achieved 3D human motion generation using various approaches including language modeling, they mostly use specialized architecture and are restricted to single-human motion generation. Inspired by the success of MM-LLMs, we propose MotionLLM, a simple and general framework that can achieve single-human, multi-human motion generation, and motion captioning by fine-tuning pre-trained LLMs. Specifically, we encode and quantize motions into discrete LLM-understandable tokens, which results in a unified vocabulary consisting of both motion and text tokens. With only 1-3% parameters of the LLMs trained by using adapters, our single-human motion generation achieves comparable results to those diffusion models and other trained-from-scratch transformer-based models. Additionally, we show that our approach is scalable and flexible, allowing easy extension to multi-human motion generation through autoregressive generation of single-human motions.
a person performs a backflip
a man is walking as if to be a zombie
a person is doing rope skipping exercise in the park
a person walks forward, turns around, and walks back the way he came
Ours: A man kneels down and proposes marriage
MoMask: A man kneels down and proposes marriage
MotionGPT: A man kneels down and proposes marriage
T2M-GPT: A man kneels down and proposes marriage
Ours: A man stands motionless and then take one steps backwards to the left
MoMask: A man stands motionless and then take one steps backwards to the left
Ours: A person jumps and spins in the air 360 degrees counterclockwise
MoMask: A person jumps and spins in the air 360 degrees counterclockwise
two people execute kicks to each other while standing
one person prepares to strike while the other prepares to block the attack
one lifts the right arm to greet the other with a wave
both people engage in a fencing bout, exchanging swift sword blows.
The following captions are generated by our MotionLLM.
a person walks forward while holding arms out as if to be a zombie
the person is walking on a balance beam
a person walks backwards in zig-zag motion
a person uses their left hand to open a bottle, drinks from it, then places the bottle back down
The following prompts are translated using DeepL.
English: A person first turns left, and then goes forward
German: Eine Person wendet sich zuerst nach links und geht dann vorwärts
Chinese: 一个人先向左转,然后向前走
French: Une personne tourne d'abord à gauche, puis avance